The agent writes tests. They pass. Code ships. Then you realize: the tests verified what the code does, not what it should do.
TDD assumes the developer knows what success looks like. Humans carry that knowledge implicitly — years of domain experience, context from conversations, intuition about edge cases. Agents don’t. They have only what’s in the prompt and codebase, plus some vibes from their training. They can vibe scenarios, but there’s no guarantee of completeness.
This post covers how to make requirements explicit before implementation begins.
The Agentic TDD Gap
TDD is elegant. Red-green-refactor. Tests define behavior. Implementation follows specification. For humans, it mostly works — though let’s be honest, writing tests is the boring part. The structure forces you to think about how your code will behave, but tests that verify implementation instead of requirements happen to humans too. Just less severely, because we have general understanding to fall back on.
Here’s the thing: for humans, documentation and requirements are a huge cognitive burden. It’s a different type of work that doesn’t feel like you’re moving the needle. Writing code feels productive. Writing specs feels like overhead. So humans skip it, or do it poorly, or do it after the fact.
Agents don’t have this problem. Documentation, requirements, test plans — the cognitive cost is basically zero. They don’t get bored. They don’t feel like they’re wasting time. They just need a system to follow. Not “be a TDD expert” — that’s a persona. A procedure: research requirements, document acceptance criteria, map tests to ACs, then implement.
Humans bring years of domain knowledge to TDD. They’ve had the meetings, seen the prior projects, developed intuition about edge cases. When something’s unclear, they ask. Agents have none of this. They see only what’s in the prompt and codebase — no intuition, just pattern matching. They don’t even know what questions to ask.
So agents write tests that verify implementation details (HOW), not requirements (WHAT).
# Implementation-driven (BAD)
def test_uses_threadpool():
"""Verify ThreadPoolExecutor is used."""
# Tests HOW, not WHAT
# Requirement-driven (GOOD)
def test_function_works_in_async_context():
"""Verify function works when called from async context."""
# Tests WHAT the requirement specifiesWe already solved the instruction problem. In Claude Code Plugins, I covered why “procedures, not personas” matters — “You are a TDD expert” is useless, but “Run tests before implementing, verify failures before fixes” is actionable. For the full methodology on building skills that encode procedures, see The Agent Skills series.
But skills assume requirements exist. Even with perfect procedural skills, if the agent doesn’t know what success looks like, it produces meaningless tests. Skills cover HOW. They don’t cover WHAT.
The Decision Checklist
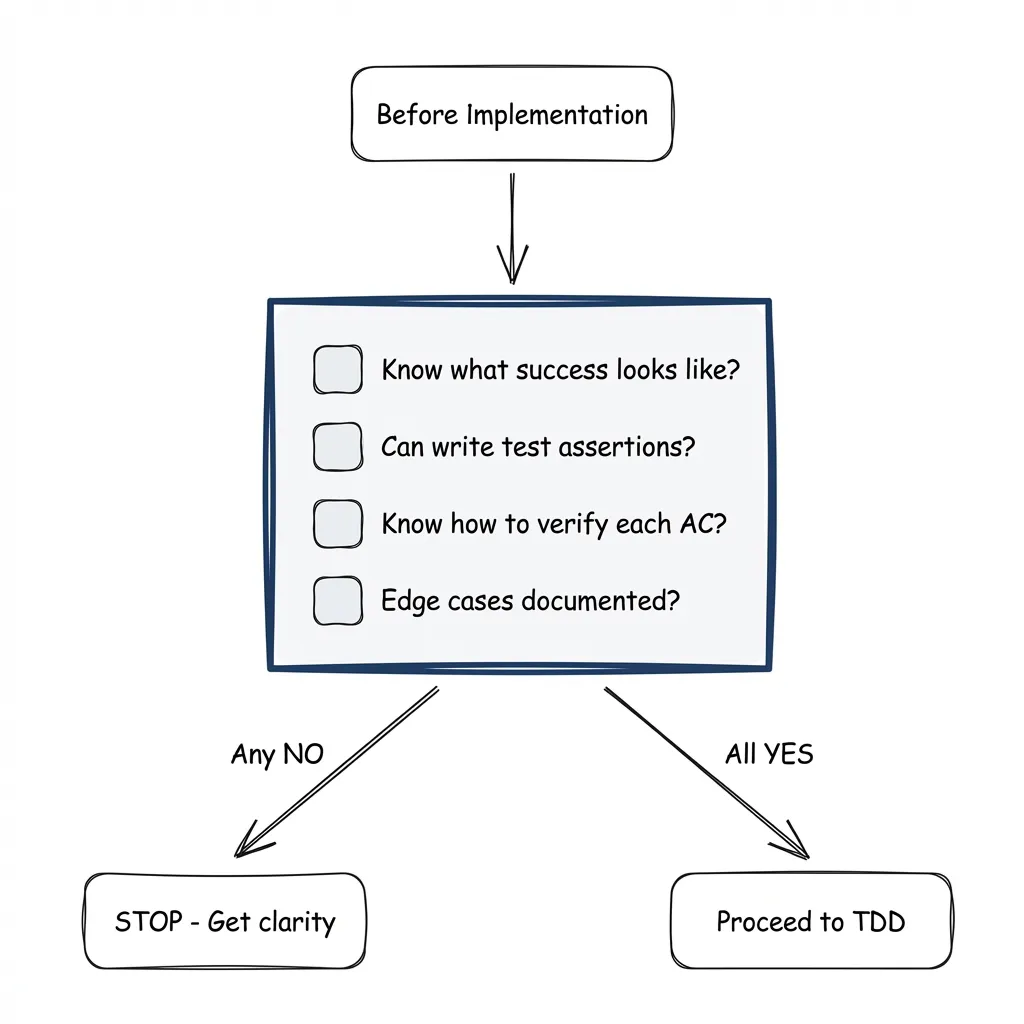
Before writing a single test, answer four questions:
- I know EXACTLY what success looks like for this task
- I can write specific test assertions from the acceptance criteria
- I know how to verify each acceptance criterion
- All edge cases are documented
If any answer is NO → Stop. Get clarity first.
Example — unclear vs clear:
Unclear: “Add model validation”
- What models? Which validation rules? What happens on failure?
- Agent will guess. Guesses become implementation details. Tests verify guesses.
Clear:
- AC1: Validate model names against provider’s model list
- AC2: Return helpful error with suggestions on invalid model
- AC3: Cache model list for 24 hours
- AC4:
--refresh-modelsflag on the main CLI command to force cache refresh
Now the agent can write meaningful tests because the requirements are explicit.
The Research Command
The pattern: separate research from implementation.
When implementation starts, the agent is already thinking about code. Requirements get discovered mid-implementation. Changes cascade. Tests get adjusted to match code. That’s a TDD violation.
The fix: a research phase that happens BEFORE implementation claims the task.
I built a /research command for this:
/research imagefactory-v2-7no2What it does:
- Loads task from beads
- Validates requirements (checks PRODUCT_SPEC, design docs)
- Researches the codebase — looks for implementation patterns, similar code, files to modify
- Answers the decision checklist
- Creates research artifact with:
- Requirements summary (acceptance criteria)
- Test plan (TDD-ready)
- Architecture notes (files to modify, patterns to follow)
- Questions/unknowns
- Implementation checklist
- Labels task:
research:completeorresearch:blocked
When questions arise during codebase research, they get documented too. By the time an implementation agent picks up the task, it’s already researched — just take it and do it.
Research artifact structure:
# Research: Add model validation (imagefactory-v2-7no2)
**Status**: ✅ Ready for implementation
**Requirements Source**: PRODUCT_SPEC.md Feature 11
## Requirements Summary
- AC1: ModelProvider ABC with discover_models(), validate_model()
- AC2: Provider implementations for Anthropic, Google, fal.ai
- AC3: File-based cache with 24h TTL
...
## Test Plan (TDD-Ready)
1. test_model_provider_interface - Verify ABC enforcement (AC1)
2. test_provider_registry_caching - Cache TTL behavior (AC3)
...
## Questions/Unknowns
✅ Q1: Which providers in Phase 1? → Anthropic, Google, fal.ai (confirmed)
❓ Q2: Cache location? → ASK USER
## Decision Checklist
- [x] I know EXACTLY what success looks like
- [x] I can write specific test assertions
- [x] I know how to verify each acceptance criterion
- [x] All edge cases documented
**Verdict**: ✅ READY FOR IMPLEMENTATIONResearch is READ-ONLY. It doesn’t modify code. It produces an artifact that makes implementation mechanical.
For a working example, see the research workflow in the demo project.
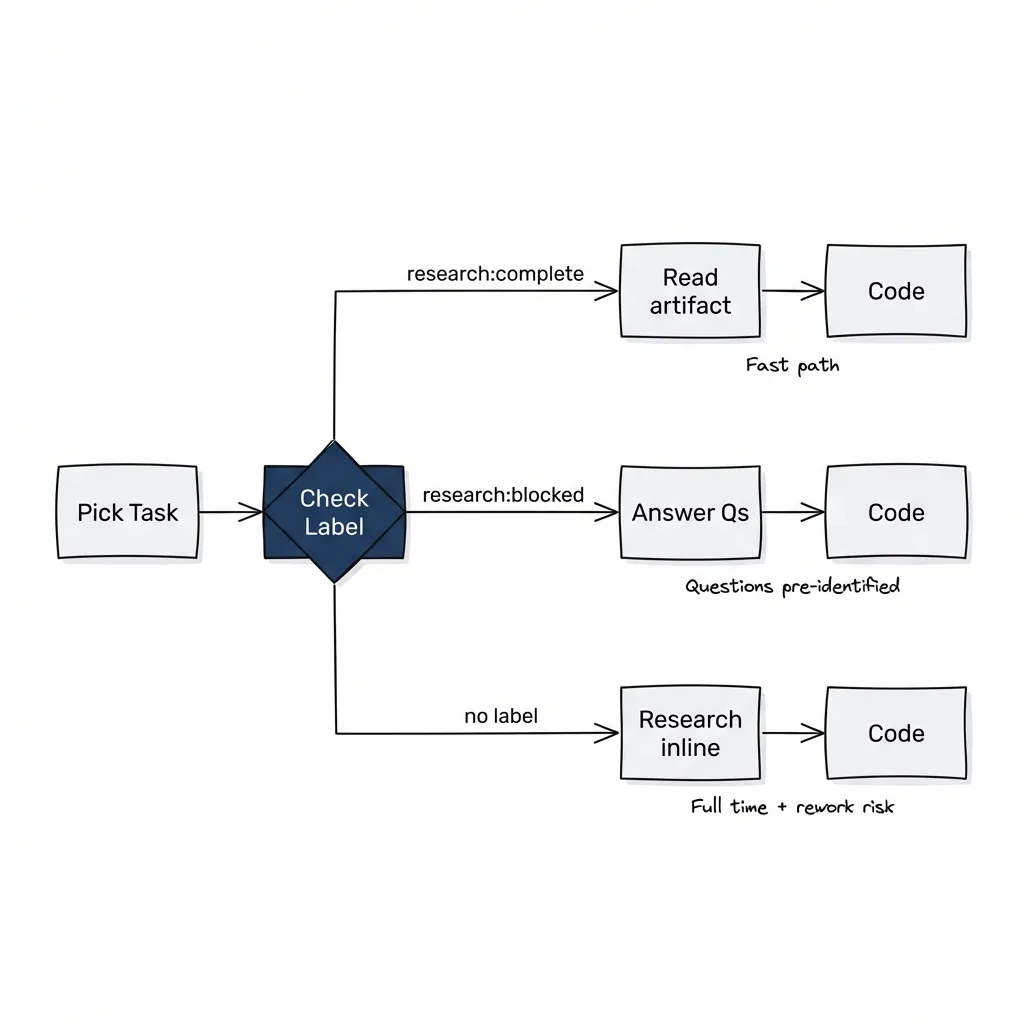
Three Paths
When an implementation agent picks up a task, it checks for the research label:
bd show <task-id> | grep "Labels:"Path A: research:complete ✅
- Research artifact exists with “READY FOR IMPLEMENTATION”
- Agent reads artifact, skips requirements research
- Goes straight to TDD (tests are already mapped to ACs)
Path B: research:blocked ⚠️
- Research artifact exists but has unresolved questions
- Agent reads questions, asks user
- User answers, updates requirements docs
- Agent updates artifact, changes label to complete
- Proceeds to implementation
Path C: No label 📝
- No research done
- Agent does requirements research inline
- Takes full time, questions emerge mid-implementation, risk of rework
Research is optional but worth it. Without it, implementation takes longer and requirements emerge mid-code.
Parallel Research
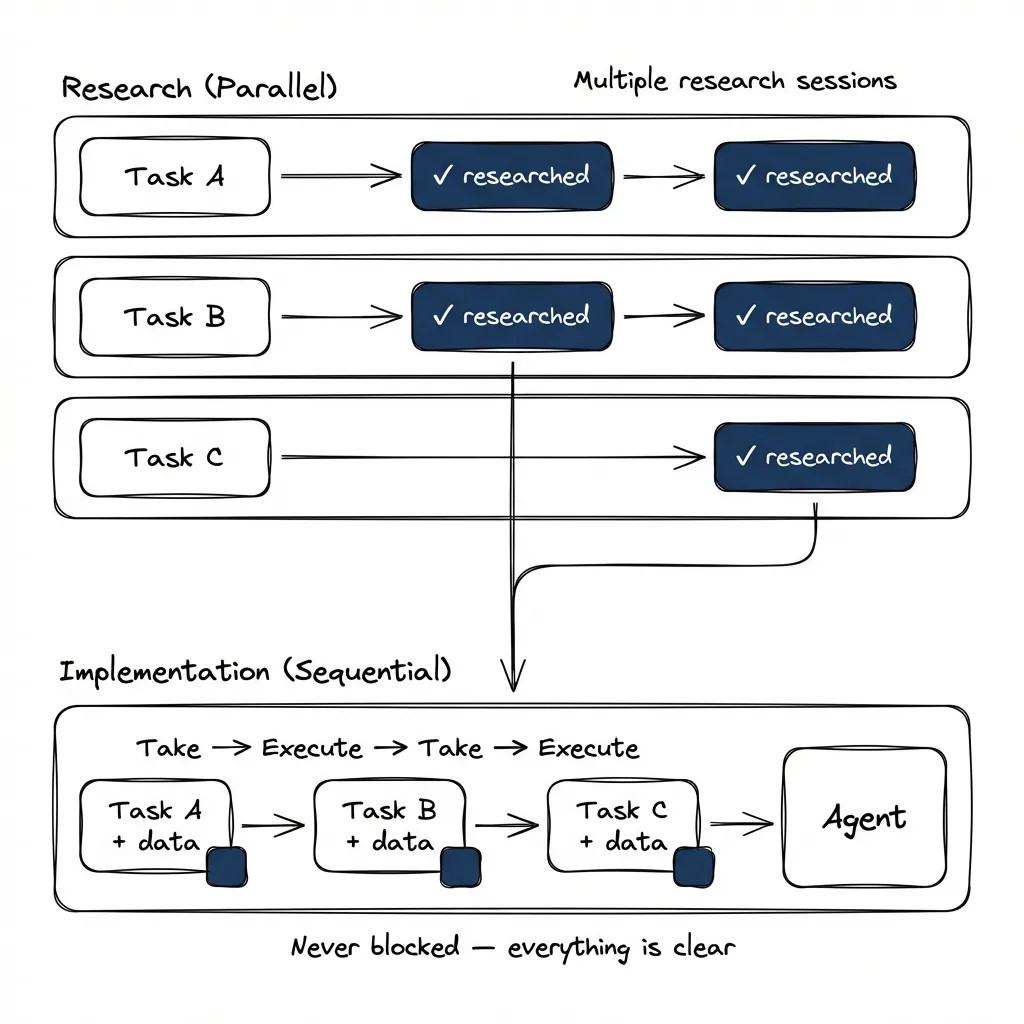
In my projects, tasks are often sequential — one builds on another, so I can’t run multiple implementations in parallel using git worktrees. Implementation becomes the bottleneck. This isn’t true for every project, but even when tasks are independent, splitting research from implementation is valuable because they’re different modes. Implementation is “go execute.” Research is interactive — you research something, we talk about the path forward.
Research can be parallelized. It’s read-only — doesn’t modify code. Multiple research sessions can run simultaneously, each producing an artifact for a different task.
The workflow:
# Session 1: Research upcoming tasks
/research imagefactory-v2-7no2 # → research:complete
/research imagefactory-v2-5czx # → research:blocked (has questions)
/research imagefactory-v2-a91s # → research:complete
# Session 2: Implementation (separate conversation)
bd show imagefactory-v2-7no2 # Has research:complete
# Read artifact, go straight to codingEven blocked research saves time. Without it, you discover unknowns mid-implementation, have to stop, ask the user, wait. With blocked research, questions are already documented — get answers immediately.
In my experience, no research means maybe an hour including discovery. Pre-identified questions cut that roughly in half. Complete research? Five minutes to read the artifact, then you’re just executing.
Research as Task Data
My current approach: research artifacts in .claude/research/task-id.md
The problem is scattered files that aren’t atomic with task commits. You have to know to look there. They get out of sync with the task.
Better approach: keep research IN the beads task.
Beads has fields for this:
--notes: Implementation notes, research summary--design: Architecture decisions, test plan
Now it’s atomic — commit task, commit research. Single source of truth. bd show <id> shows everything.
# Instead of creating .claude/research/task-id.md
# Put research summary in beads task
bd update imagefactory-v2-7no2 --design="$(cat <<'EOF'
## Requirements (PRODUCT_SPEC Feature 11)
- AC1: ModelProvider ABC
- AC2: Provider implementations
- AC3: File-based cache, 24h TTL
## Test Plan
1. test_model_provider_interface (AC1)
2. test_provider_registry_caching (AC3)
## Decision Checklist: All YES
EOF
)"
bd label add imagefactory-v2-7no2 research:completeTask data stays with the task. Research is task data.
The Bigger Picture
This series covered context through MCP, skills for repeatable work, verification patterns, task tracking with beads, and sub-agents for parallel exploration. Requirements sit underneath all of it. Without them, the other pillars don’t work — skills tell the agent how to do things but not what to do, quality gates verify implementation but not correctness.
My current hypothesis: BDD, domain-driven design, and formal use case analysis become powerful leverage for AI agents. Structured requirements modeling — scenarios, invariants, constraints, behavior specs — is almost free to create and maintain when AI handles the documentation cost. If I can model system behavior in a structured way that anyone can read and review, that specification becomes the reference point for the agent when writing code, running tests, validating behavior.
The flow I’m testing: design use cases → define scenarios → define invariants and schema constraints → write behavior tests that verify business rules → agent implements against those tests. At any point, the agent can run behavior tests and know if it’s on track.
I don’t have a strong preference for BDD specifically. What I want is a systematic way to surface requirements during analysis — a thinking pattern that doesn’t miss scenarios, constraints, edge cases. I’ll share results as I get them. If you’re working on similar problems, I’d like to hear about it.
Try It
Before your next task, answer the four questions. If any answer is NO, don’t start. Research first.
The time “lost” to research is time saved debugging unclear requirements later. I’ve watched agents spend 90 minutes implementing something that took 30 minutes to redo once requirements were clear.
The workflow: /research <task-id> → artifact → research:complete → implementation as execution.
Final post in the Agentic Development Workflows series. Previously: Stop Using Claude Code Like a Copilot, MCP Setup, Plugins, Verification Patterns, Beads for Multi-Session Tasks, and Sub-Agents. For building skills that encode expertise, see The Agent Skills series.