Your agent skipped step 4. Again.
You wrote the workflow file. Requirements validation, regression test, implementation, quality gate, commit. Five steps, written in order. The agent followed them perfectly for the first three tasks. Then context grew. Compaction happened. By task six, it’s doing implement-then-commit. No regression test. No quality gate.
It didn’t hallucinate. It didn’t lose the ability. It got tired.
A surgeon at hour 14 doesn’t forget how to suture — they forget to check the chart. The skill is intact. The discipline erodes. Your agent works the same way. It can still analyze code, write tests, review diffs. What it can’t do is remember that it’s on step 3 of 5, that step 4 is a quality gate, and that step 5 requires step 4’s output.
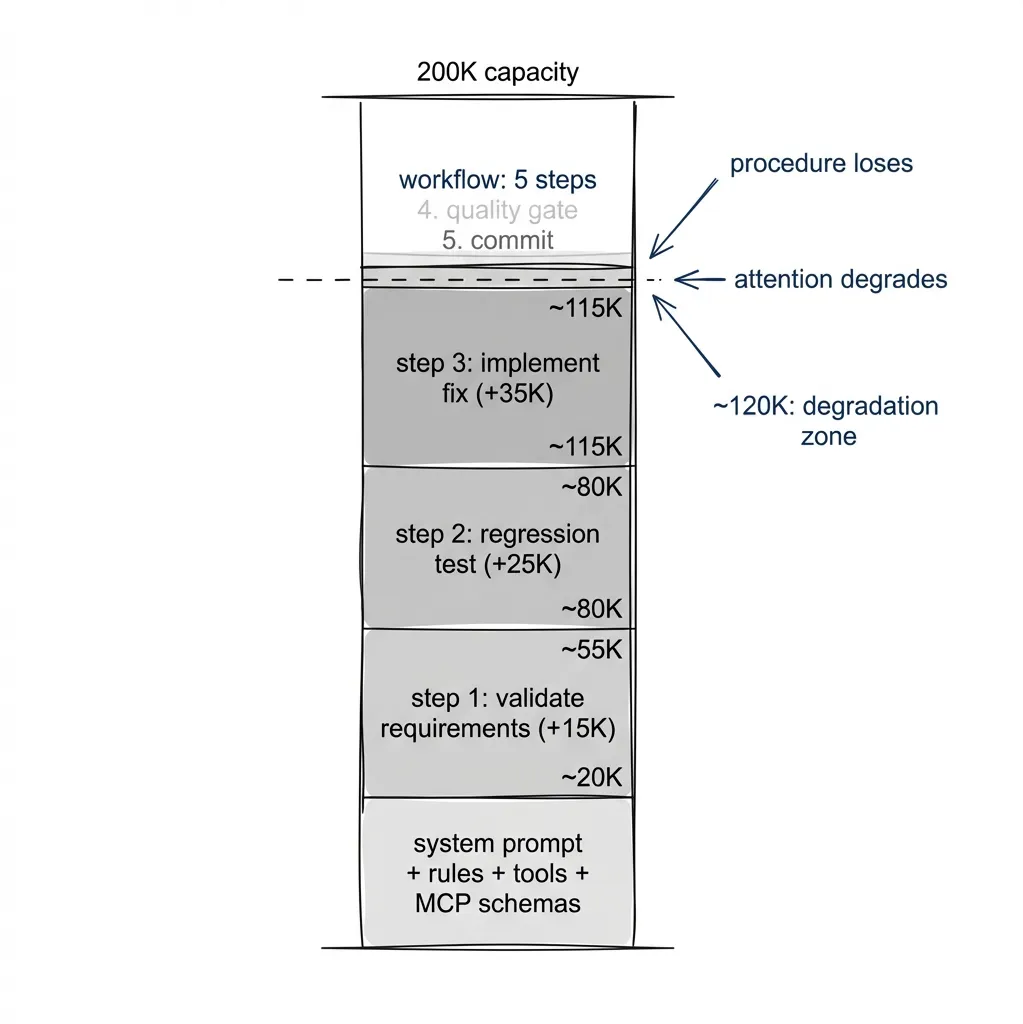
The context window fills with implementation details: file diffs, test output, error traces, code it just wrote. The workflow instructions are still there, somewhere, buried under 17K tokens of actual work. The attention budget gets spent on the code, not the procedure. Steps get skipped not because the agent can’t do them, but because the procedure loses the competition for attention.
Why Workflow Files Break
In the previous series, we built a layered system: CLAUDE.md for project context, rule files for quality gates, beads for persistent task tracking. Workflow files in .claude/rules/ describe multi-step processes. The agent reads them at session start. For short sessions and simple tasks, this works.
It breaks on long ones.
Your bug-reporting workflow says: validate requirements, write regression test, implement fix, run quality gates, commit. The agent starts step 1. Reads the spec. Checks acceptance criteria. Context grows by 2K tokens. Step 2: writes a regression test. Reads existing tests for patterns, generates new test code, runs it, confirms failure. Another 5K tokens. Step 3: implements the fix. Explores codebase, reads affected files, writes code, handles edge cases. 10K more tokens.
By step 4, the original workflow instructions are buried under 17K tokens of artifacts from the work itself. The five-step procedure competes for attention against the implementation details. Procedure loses. Better prompts help (structured output, explicit step tracking, numbered checklists) but they can’t eliminate it. The root cause is structural, not linguistic.
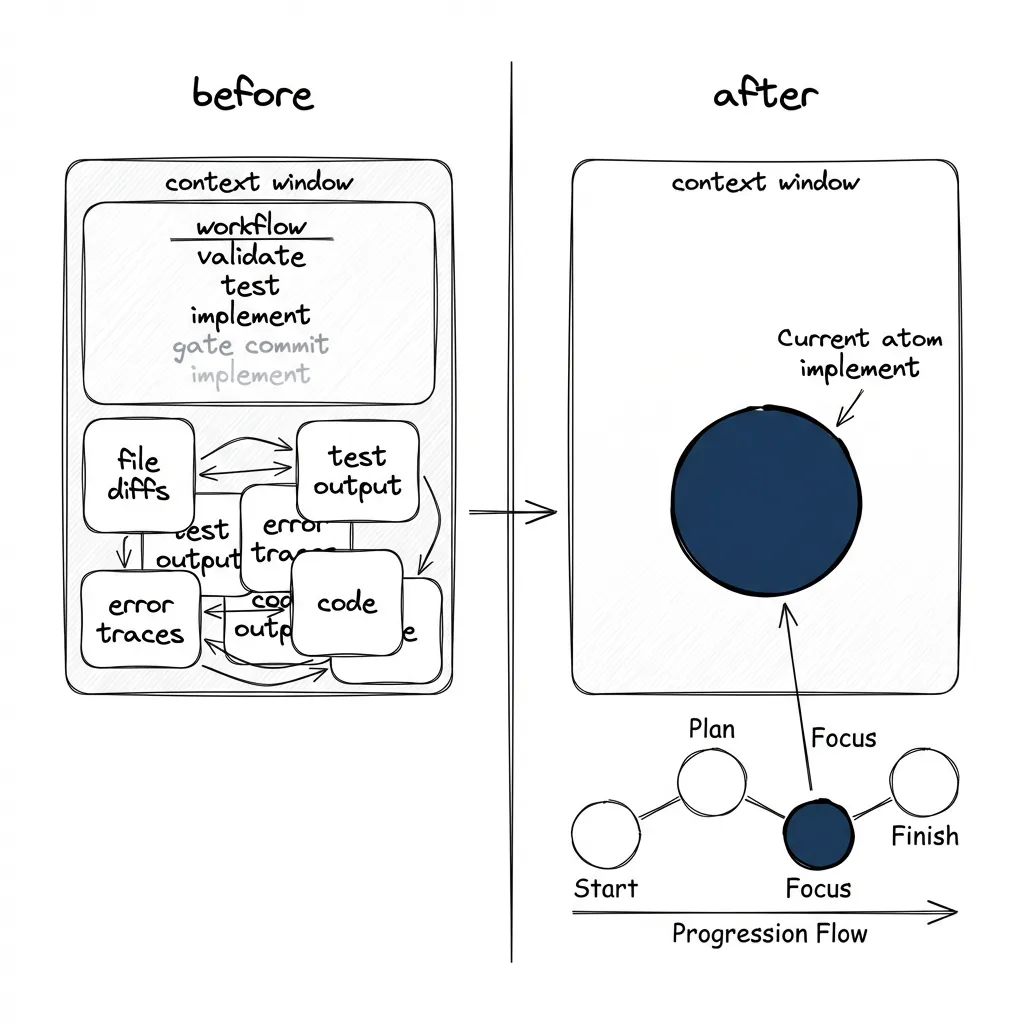
The Fix: Decouple Procedure from Cognition
Stop asking the agent to track where it is in a workflow. Put that information outside the agent, in a structure it can query on demand.
Beads already does half of this. bd ready shows what’s available. Dependencies enforce execution order. Task descriptions are self-contained. The agent doesn’t have to remember what comes next — the graph knows.
What’s missing: the tasks themselves. Someone has to create them, in the right order, with the right descriptions and dependencies. Doing that manually for every bug fix, every feature, every BDD scenario defeats the purpose.
A formula is a YAML template that describes a workflow as a sequence of atomic tasks. A molecule is the concrete set of beads tasks created by “baking” a formula with specific input variables. Baking is the transformation: formula + variables = molecule.
Here’s the payoff. Eight tasks get baked from a formula, fully linked with dependencies, under one epic. The agent’s workflow loop becomes:
bd ready # What's next?
bd show <atom> # Read the self-contained instructions
# ... execute ...
bd close <atom> # Done
# repeatThe agent doesn’t track any workflow state. The procedure lives in the dependency graph, not in the context window.
The formula that produces these tasks, trimmed from task-execute.yaml:
name: task-execute
iterate:
over: "TASK_IDS"
item_var: "TASK_ID"
barrier_label: "atom:commit"
atoms:
- id: "research-{TASK_ID}"
title: "Research {TASK_ID}"
description: |
Execute research for beads task {TASK_ID}.
1. Read the task: `bd show {TASK_ID}`
2. Explore the codebase
3. Check documentation (Ref MCP)
4. Store findings in the bead: `bd update {TASK_ID} --append-notes "..."`
depends_on: []
- id: "review-{TASK_ID}"
title: "Architect review of {TASK_ID}"
description: |
Read research findings. Evaluate approach soundness,
risk coverage, spec fidelity. Rate findings LOW/MEDIUM/HIGH.
depends_on: ["research-{TASK_ID}"]
- id: "implement-{TASK_ID}"
title: "Implement {TASK_ID}"
description: |
Follow TDD. Red: failing test. Green: minimum code. Refactor.
Run `make quality` before closing.
depends_on: ["review-{TASK_ID}"]
- id: "commit-{TASK_ID}"
title: "Commit {TASK_ID}"
description: |
`git add <specific-files>`. `git commit -m "type: description"`.
depends_on: ["implement-{TASK_ID}"](Beads now supports molecules natively via bd cook. The examples here use YAML; the official format is TOML. The concepts and patterns are the same.)
The {TASK_ID} placeholders get replaced when you bake:
python cook_formula.py \
--formula task-execute.yaml \
--var "TASK_IDS=beads-123 beads-456" \
--epic-title "Execute: beads-123 beads-456"
# Output:
# Epic: beads-789 — Execute: beads-123 beads-456
# beads-123: beads-790 — Research beads-123
# beads-123: beads-791 — Architect review of beads-123
# beads-123: beads-792 — Implement beads-123
# beads-123: beads-793 — Commit beads-123
# beads-456: beads-794 — Research beads-456
# ...
# Cooked 8 atoms under epic beads-789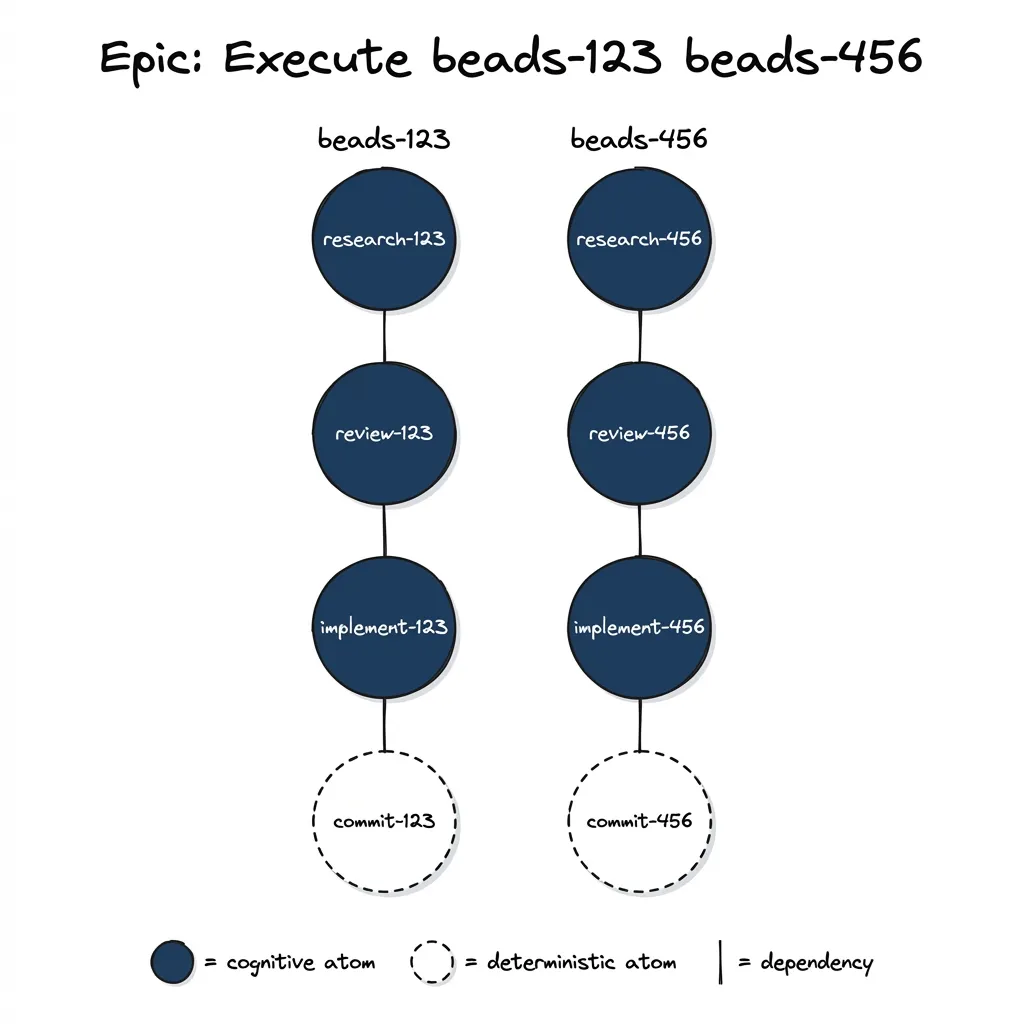
What Makes This Work: Self-Contained Atoms
The formula above has four atoms per task. It gets more interesting when atoms carry enough context to run on their own.
The implement atom in production:
- id: "implement-{TASK_ID}"
title: "Implement {TASK_ID}"
description: |
Implement beads task {TASK_ID} following the researched and reviewed plan.
## Prerequisites
Run `bd show {TASK_ID}`. The bead contains everything you need:
- **Description**: What the task is
- **Notes**: Research findings, architect review, any refinements
- **Design**: Architecture decisions and implementation plan
Read ALL of these before writing any code.
## Workflow
Follow TDD (Red-Green-Refactor):
1. **Red**: Write failing test. Confirm it fails for the right reason.
2. **Green**: Write minimum code to make the test pass.
3. **Refactor**: With passing tests as safety net.
4. **Quality gate**: `make quality`
## If Blocked
Update task notes explaining the blocker. Leave atom open.
## If Successful
Close the original task: `bd close {TASK_ID}`
acceptance: "make quality passes. Original task {TASK_ID} closed."
depends_on: ["review-{TASK_ID}"]Every atom has instructions, preconditions, and acceptance criteria. The atom is the complete interface. No external procedure to track.
Why this works in practice:
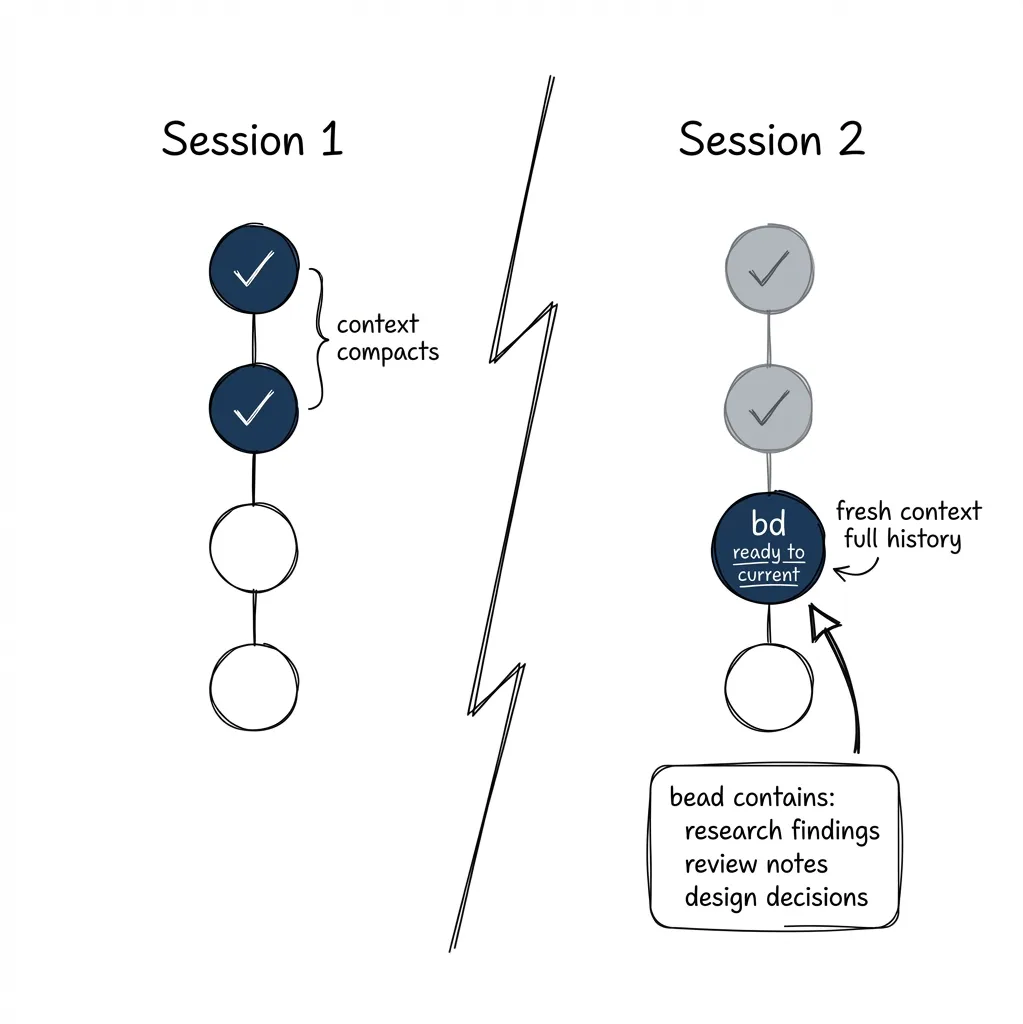
Crash recovery. Context compacts mid-workflow. The agent runs bd ready. Gets the next unclosed atom. All prior work (research findings, review notes, architecture decisions) is stored in the bead itself, not in context. The research atom wrote its findings to bd update {TASK_ID} --append-notes "...". The implement atom reads them from bd show {TASK_ID}. Nothing lost.
Session boundaries. New day, new session, fresh context window. Same loop: bd ready, bd show, execute, bd close. The atom has everything the agent needs to pick up where the previous session stopped.
The deterministic sandwich. Atoms can be cognitive or deterministic. Line them up and you get a pattern:
| Atom | Type | What it does |
|---|---|---|
| research | cognitive | Read codebase, identify patterns, store findings |
| review | cognitive | Evaluate approach against requirements |
| triage | deterministic | Route based on review verdict (ALL_LOW / NEEDS_REFINEMENT / BLOCKED) |
| implement | cognitive | Write code following TDD |
| commit | deterministic | git add, git commit, verify with git log |
Cognitive atoms do the thinking. Deterministic atoms enforce discipline. Quality gates become easy to enforce: they’re discrete tasks with acceptance criteria, not steps the agent has to remember while doing something else.
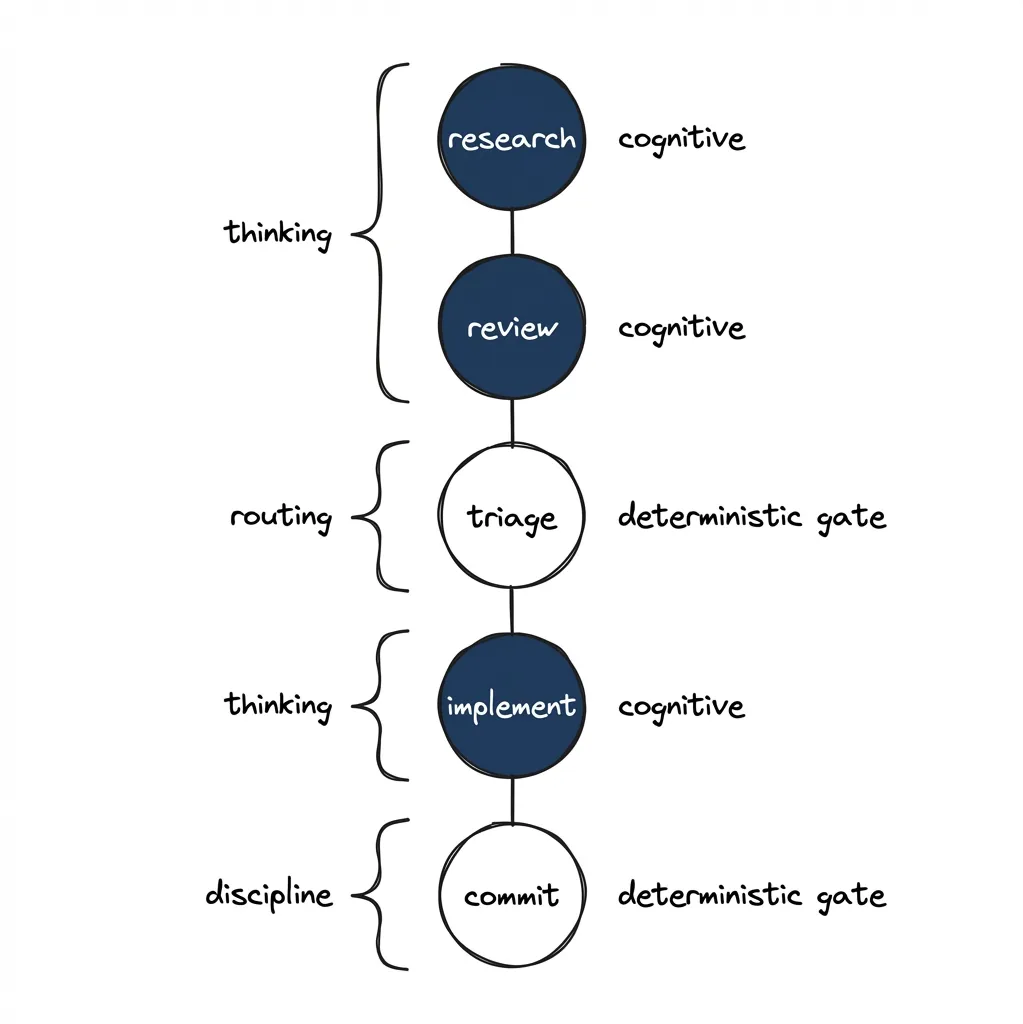
The triage atom reads the architect review verdict and routes: clean review proceeds to implementation, medium findings trigger refinement, high findings block for human input. The routing logic is deterministic, just pattern matching on the verdict. It sits between two cognitive atoms that do require judgment. The triage atom can dynamically add steps to the graph — we’ll cover this routing pattern in detail in the next post.
When an atom fails (the quality gate doesn’t pass, the review flags a blocker) the atom stays open. The dependency graph prevents downstream atoms from starting. The failure is visible in bd ready, and either the agent retries or a human intervenes. Failures are explicit and contained, not silently swallowed mid-workflow.
I’m building an application for agentic image generation and refinement, the entire codebase written end-to-end with this approach. The molecular version of BDD development completes all 12 steps on every run. The cognitive version, same methodology loaded as a single prompt, starts skipping gap analysis after the third use case. Same methodology. The execution structure makes the difference.
Why This Keeps Happening
The agent is handling two different jobs at once.
Cognitive work: analyze this code, write this test, review this diff, find the bug. LLMs are good at this.
Procedural work: remember which step you’re on, track what comes next, verify you did step 4 before starting step 5. This is bookkeeping.
One system. Both jobs. Same context window, same attention budget. Google DeepMind and MIT studied this tension across 180 agent configurations. On tasks requiring strict sequential reasoning, every multi-agent variant they tested degraded performance by 39-70%. While their study focused on multi-agent coordination, the same principle applies within a single agent’s context: tracking procedural state consumes cognitive budget that should go to the actual task.
The procedural load eats the cognitive capacity.
Spotify’s Honk team found the same thing empirically. Their homegrown agent performed best with “strict step-by-step prompts.” Claude Code performed better with “prompts that describe the end state.” Step-by-step is procedural guidance. End-state is cognitive freedom. Two agents, two optimal modes — consistent with the idea that procedure and cognition require different approaches.
Why the Industry Makes It Worse
Open any context engineering guide or agentic best practices document today and you’ll find something like: build a minimal harness, give the model few tools, let it figure things out through reasoning. And the model will. It will do five web searches, run an analysis pass, discover the pattern it needs, and arrive at the right approach.
“Figure it out” has a cost. Every reasoning step burns thinking tokens. Every exploratory search burns tool calls. The model smashing against a problem ten times before finding the answer on the eleventh costs you ten times more than a clear instruction would have. I argued the same thing in the skills post: if you add a skill about LangGraph debugging, the agent doesn’t need to rediscover the debugging pattern through five web searches. It reads the skill, follows it. The knowledge is in context, not discovered through exploration.
It’s the same principle as onboarding a smart new hire. You can drop them in with no documentation and say “you’ll figure it out.” They will, eventually. How many avoidable mistakes? Onboarding works because encoding institutional knowledge is cheaper than rediscovering it. Formulas are onboarding for agents.
Step-skipping also happens with fresh context. The model can rationalize. “These test failures look pre-existing, I’ll close the task.” “This step seems redundant after what I just did.” “I thought that wasn’t really important.” The model reasons its way around the procedure. A quality gate that says “do not close if tests fail” is not a judgment call. There’s no room for reasoning about it. It’s a gate. But if the gate is a line in a workflow file competing for attention against 17K tokens of implementation context, the model has the cognitive freedom to talk itself past it.
The “model will figure it out through thinking” approach benefits one party: the company selling you tokens. Not you.
What This Enables
Scaling workflow complexity. The req-bdd-develop.yaml formula has 12 atoms in a linear pipeline: read context, discover step library, verify business rules, three derivation passes, reflection gate, write feature file, lint and scan, coverage matrix, commit, and spawn downstream validation. No agent could reliably execute all 12 steps from a workflow.md file. As 12 separate atoms, each one is simple. One task, one description, one acceptance criterion. The complexity lives in the dependency graph, not in the context window.
Reusable workflow templates. task-execute.yaml works for any beads task that needs research-review-implement-commit. Write the formula once, bake it for every instance. Your team’s dev methodology becomes YAML files in git, applicable to any project with beads installed.
Skills ship with formulas. In practice, each skill ends up with two versions. The cognitive version (the skill file) handles simple cases where context exhaustion isn’t a risk. The molecular version (skill + formula) handles complex cases. /mol-execute beads-123 cooks the formula, creates the atom graph, and starts walking it. One command. If context compacts midway, the crash recovery kicks in: the next session picks up at the next ready atom.
# Cognitive version -- simple task, single session
/execute beads-123
# Molecular version -- complex task, needs crash recovery
/mol-execute beads-123 beads-456 beads-789Not everything needs a formula. For a quick bug fix or a single-file change, they’re overkill. The overhead pays off when you’re running the same workflow pattern repeatedly, or when context exhaustion is actively causing quality failures. If your tasks consistently complete in a single context window, you don’t need molecules.
And you don’t have to write formulas yourself. The agent can help: analyze situations where it tends to go off-rails, identify which steps get skipped under context pressure, suggest the corrections, and prepare the formula. You review what it proposes, refine it, and then the agent uses the same formula it helped build. The principle matters, but the execution is mostly automatic.
How This Compares
Others have found pieces of this split.
The scratchpad pattern (devin.cursorrules) is the closest in spirit. Put plan state in a scratchpad.md file. The agent updates progress as it works. Smart for single-session tasks. The problem is volatility: the scratchpad is an in-context file that compaction can summarize away. The multi-agent variant (planner + executor sharing a scratchpad) adds coordination cost on top. Beads tasks are git-backed. They survive compaction, session boundaries, context resets.
LangGraph encodes workflows as Python graphs. Each node calls the model. Deterministic execution order with model cognition at each node, the same decoupling at different complexity. Simpler infrastructure: a single Python script and beads, versus a full framework with its own deployment story. LangGraph gives you production-grade orchestration if you need it. Formulas trade that power for simplicity: YAML files, a 370-line baking script, no runtime.
Three things make this work: persistent task state so workflows survive crashes. Deterministic gates between cognitive steps — discipline becomes structural instead of aspirational. And reusable templates, because encoding methodology once beats writing it fresh every time. The research paper “Blueprint First, Model Second” backs this up: “removing structural planning responsibilities allows language models to operate with clearer context windows and more focused attention.” Their conclusion: “sometimes constraining LLM autonomy produces superior outcomes to maximizing generative freedom.”
The Shift
Your agent isn’t stupid. It’s overloaded. You gave it a six-step procedure and the cognitive work of each step and the accumulated context of everything it already did. Something had to give. The procedure gave.
The fix is structural: decouple what the agent is good at (cognition) from what it’s bad at (procedure). Put the procedure in a dependency graph. Let the agent focus on one thing at a time.
This post covers the concept. Next, we build a formula from scratch — the full YAML structure, variable templating, dependency patterns, the setup/iterate/finalize sections that handle both linear pipelines and iterative workflows.
First in the “Deterministic Agent Workflows” series. Building on the Agentic Development Workflows series (context, skills, verification, beads, sub-agents). Next: Building Formulas from Scratch.