Managing Entropy
This is Part 3 of a series on building AI skills that actually work. I chose skills over agent definitions because skills can be reused across agents — in Claude Code’s architecture, agents can’t launch other agents, but any agent can use the same skills. This part covers how to organize skills so they don’t collapse under their own weight.
Part 1 diagnosed the problem. Part 2 covered the methodology for building good skills.
Now the hard part: what happens when you have many skills?
Even good skills become a mess. Install 50 of them and watch your agent become indecisive, pick randomly, or ignore them entirely. The math of attention works against you.
How We Got Here (A Brief Detour)
I should back up and explain why this problem exists at all.
Anthropic introduced MCPs. Everyone got excited. Then everyone realized: too many tools cause model indecisiveness. The advice became “use fewer tools, rely on the model’s intelligence, give it something robust like bash and let it figure things out.”
Then skills came along. Context injection. A way to give Claude specialized knowledge without hardcoding it.
And now… we have the same problem again. Too many skills. Model indecisiveness. Except this time the failure mode is worse because skills are easier to create than tools, which means anyone can write a SKILL.md and most of them turn out poorly. Even the ones that follow Anthropic’s specification (most don’t) are often useless because they’re information packed as skills, not actions. Which is what this whole series is about.
So here we are. The architecture problem isn’t optional. It’s the only thing standing between “skills that help” and “skills that make everything worse.”
The Foundation: Progressive Disclosure
Before anything else, understand how Anthropic designed the system.
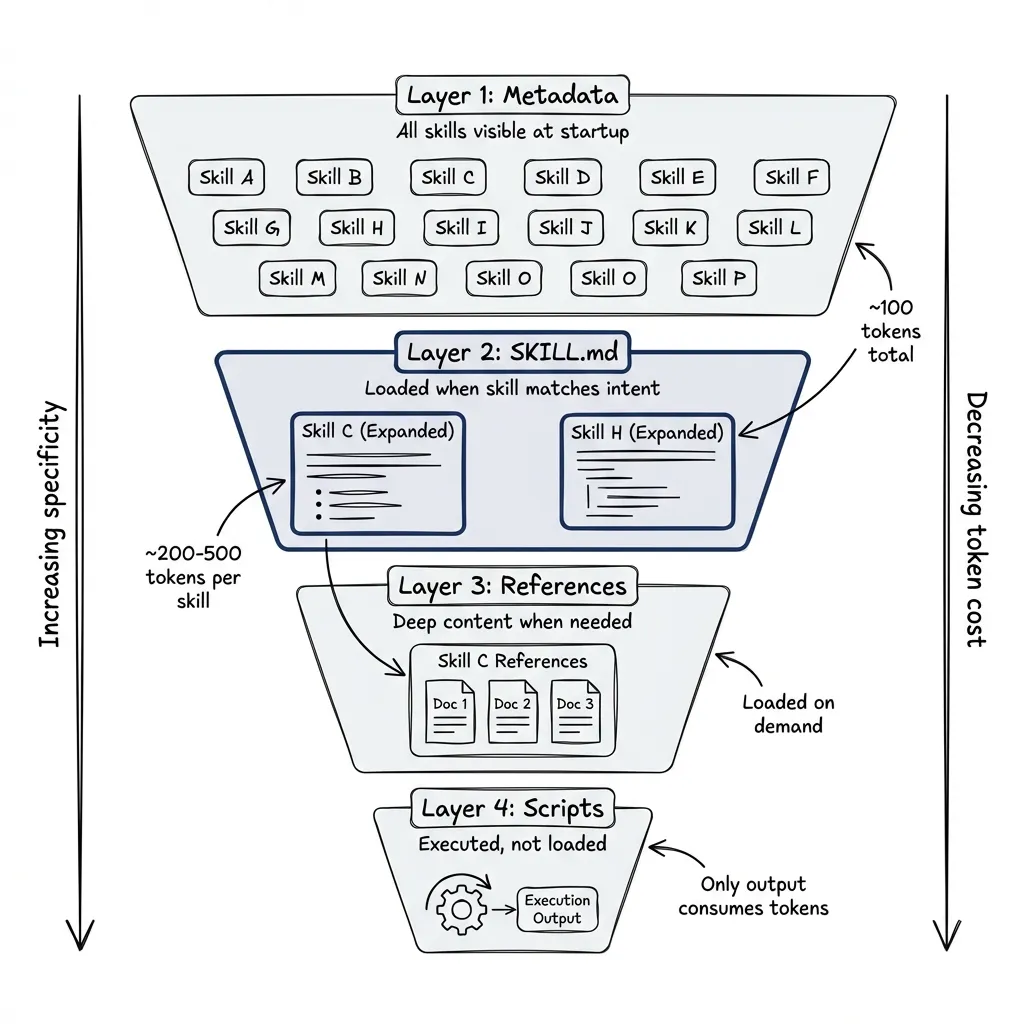
Skills load in layers:
- Metadata only (~100 tokens): At startup, Claude sees just the
nameanddescriptionfrom all skills’ YAML frontmatter - SKILL.md content: Loaded when Claude determines the skill applies
- Reference files: Loaded only when needed during execution
- Scripts: Executed without loading into context, with only output consuming tokens
This means you can have many skills available without overwhelming the context window. The skill that handles PDF processing doesn’t consume tokens when you’re working on database queries.
Anthropic’s constraints:
- SKILL.md under 500 lines
- References one level deep (SKILL.md to reference.md, not SKILL.md to guide.md to details.md)
- Forward slashes in paths (
reference/guide.md, notreference\guide.md) - Descriptions in third person (“Processes Excel files”, not “I can help you process Excel files”)
- Description includes both what the skill does AND when to use it
I’m less strict on the 500-line limit than Anthropic suggests. If the structure is right and the skill genuinely needs 600 lines, I’d rather have a complete skill than an artificially truncated one. The point is keeping things digestible, not hitting an arbitrary number.
The Entropy Trap
Even with progressive disclosure, every skill you add competes for the model’s attention at the metadata level.
Three skills with similar descriptions:
- “React component development”
- “Frontend best practices”
- “Next.js patterns”
The semantic embeddings overlap. Ask “refactor this component” and the model sees three signals pointing in roughly the same direction. Can’t distinguish them reliably.
I call this Vector Collapse. Triggers too similar. Model uncertain. The result? Indecision, random selection, or ignoring all three skills entirely.
More skills does not equal more capability. Past a threshold, more skills equals worse performance.
The solution isn’t smarter routing. Discipline.
Principle 1: Disjointness
No two skills should cover the same intent.
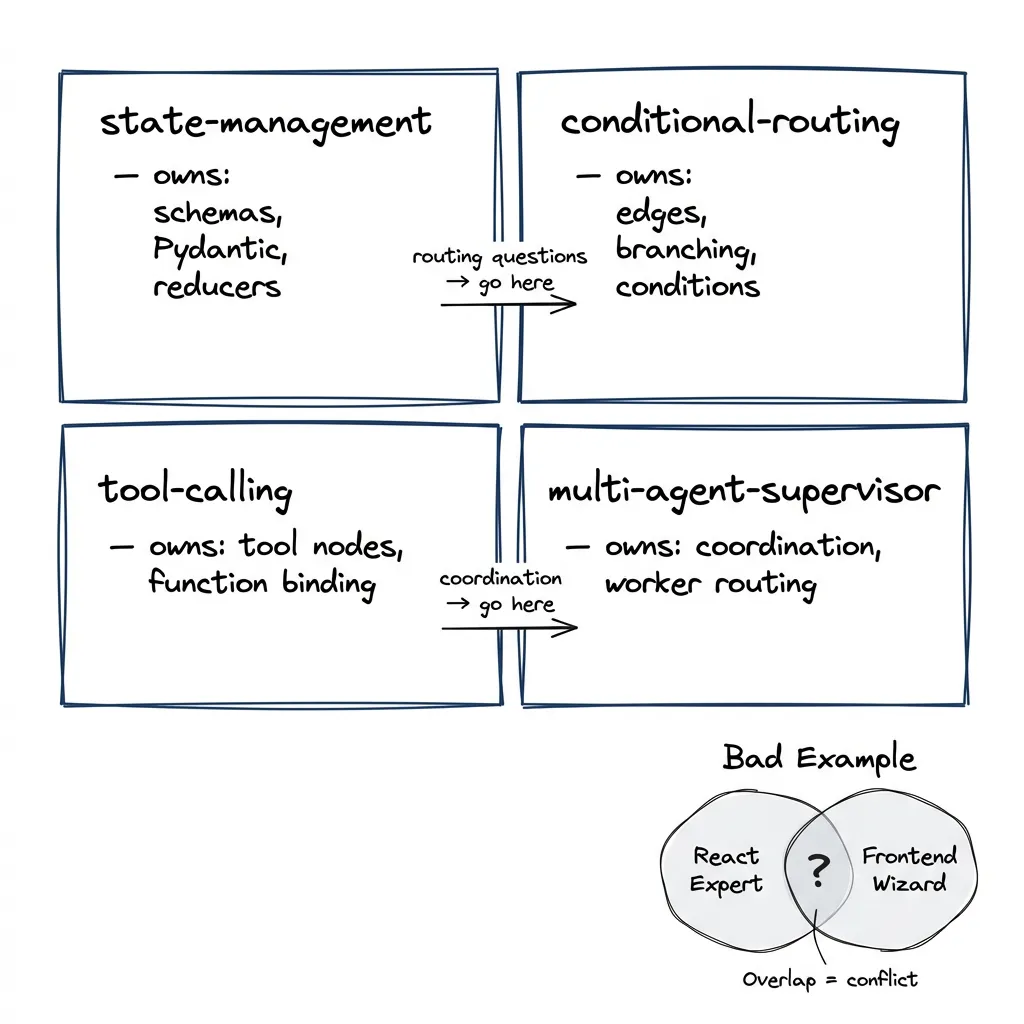
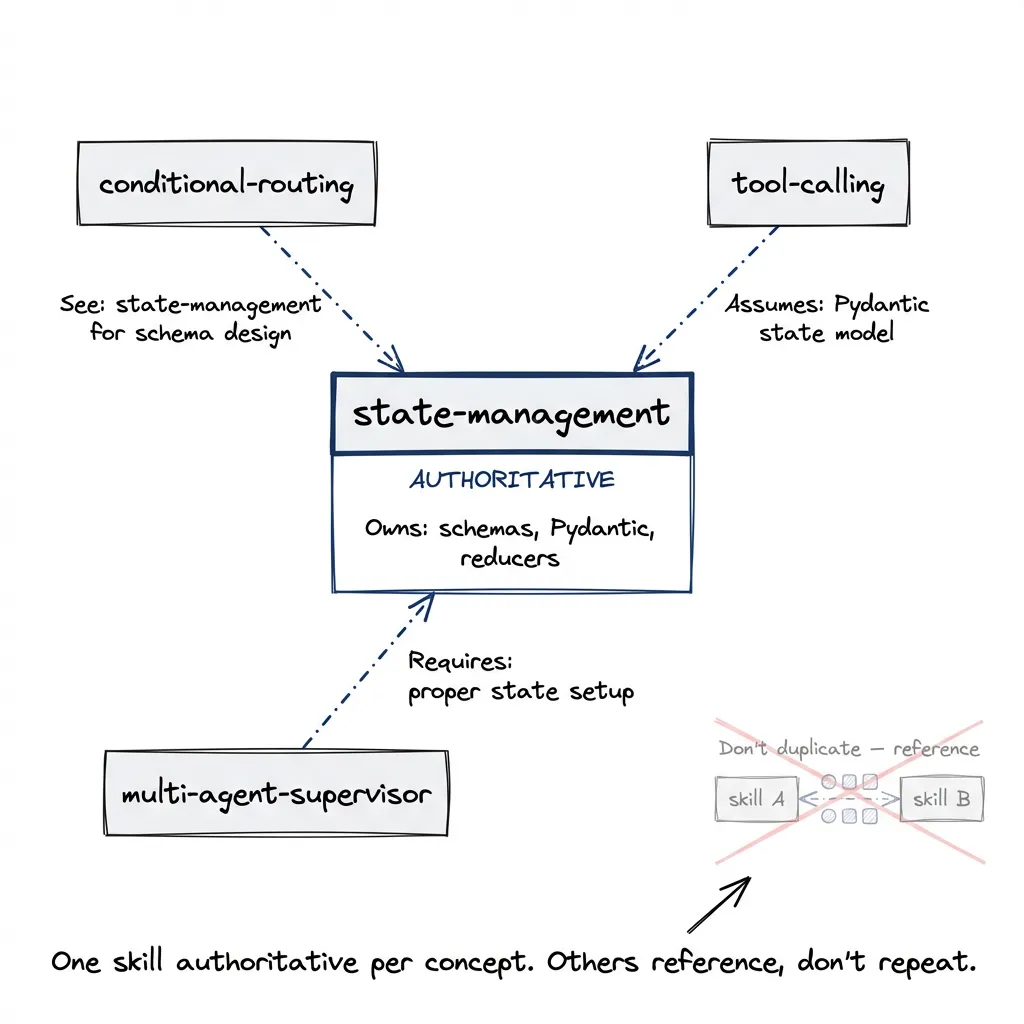
When I built the LangGraph plugin, I enforced this strictly. Each skill owns a specific use case:
langgraph-dev-state-management → State schemas, Pydantic models, reducers
langgraph-dev-conditional-routing → Edge conditions, branching logic
langgraph-dev-tool-calling → Tool nodes, function binding
langgraph-dev-multi-agent-supervisor → Agent coordination, routing between workersState management doesn’t touch routing. Routing doesn’t touch tool calling. If two skills start covering the same territory, one dies or they merge.
The test: given any user request, at most one skill should match. Two skills could handle the same request? Overlap. Fix it.
Enforcement:
Each skill declares what it owns and what it doesn’t. Trigger phrases in the frontmatter:
name: langgraph-dev-state-management
description: >
Use when user asks about "state schema", "TypedDict",
"Annotated fields", "state reducers", "MessagesState"But triggers alone aren’t enough. Anti-triggers matter too:
## Does NOT Cover
- Conditional routing (see langgraph-dev-conditional-routing)
- Checkpoint persistence (see langgraph-dev-memory-store)
- Multi-agent state sharing (see langgraph-dev-multi-agent-supervisor)The skill explicitly defers to other skills. No ambiguity.
Principle 2: Namespacing and Tiering
Multiple plugins, naming collisions. A “state-management” skill in LangGraph conflicts with “state-management” in React.
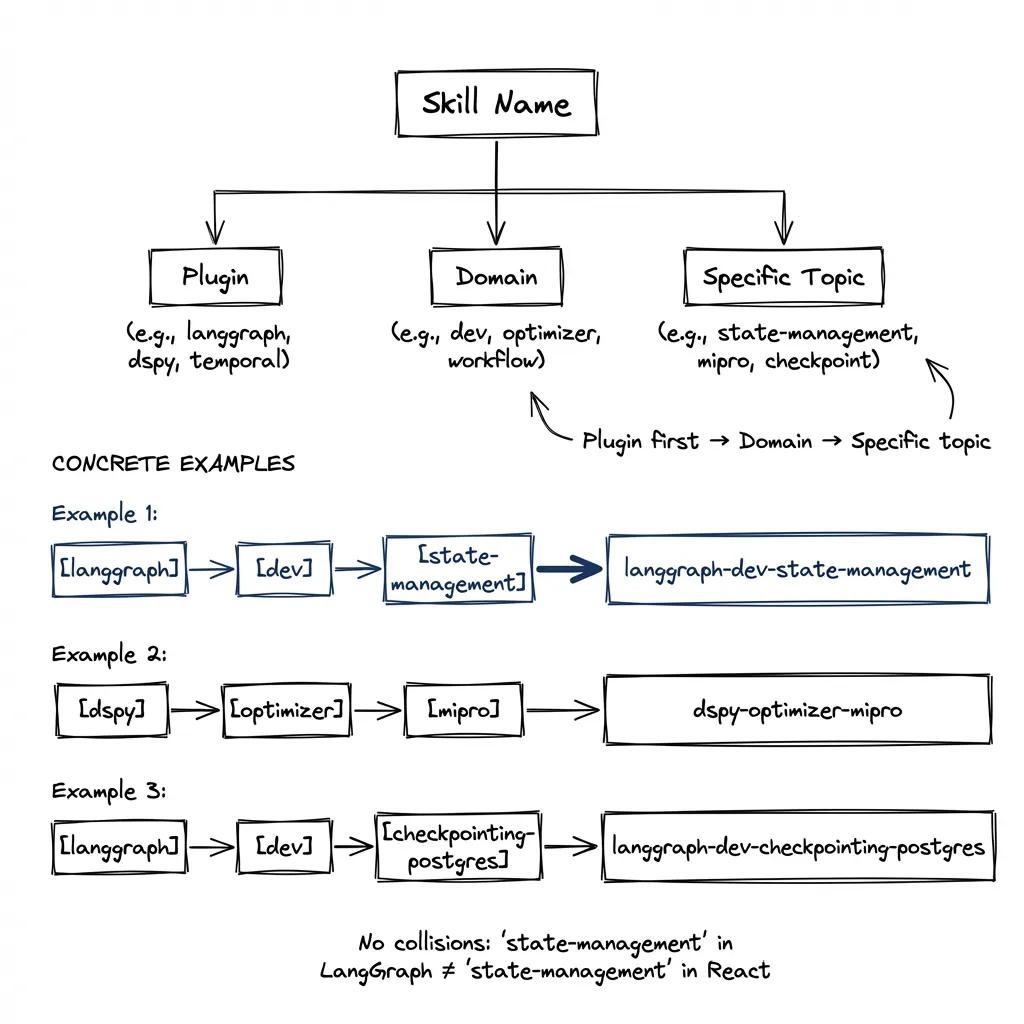
Hierarchical namespacing:
{plugin}-{domain}-{specific-topic}
langgraph-dev-state-management
langgraph-dev-conditional-routing
dspy-signature-design
dspy-optimizer-miproPlugin first. Then domain. Specific skill last.
Tiering for complexity:
Sometimes you need the same capability at different levels. Basic in-memory checkpoint for experiments. Production Postgres checkpoint with persistence.
Don’t let them compete:
langgraph-dev-checkpointing-basic → In-memory, for prototyping
langgraph-dev-checkpointing-postgres → Full persistence, production setupBasic skill triggers: “quick checkpoint,” “prototype,” “in-memory.” Production skill triggers: “postgres,” “persistent,” “production checkpoint.”
Basic skill explicitly says: “If you need production persistence, use langgraph-dev-checkpointing-postgres instead.”
No collision.
Principle 3: The Compiled Pack
You cannot effectively hot-swap skills at runtime.
The marketing dream: dynamic skill discovery, agent searches a catalog, loads skills on demand. I’ve tried this. It adds latency, introduces errors, unpredictable behavior. Not worth it.
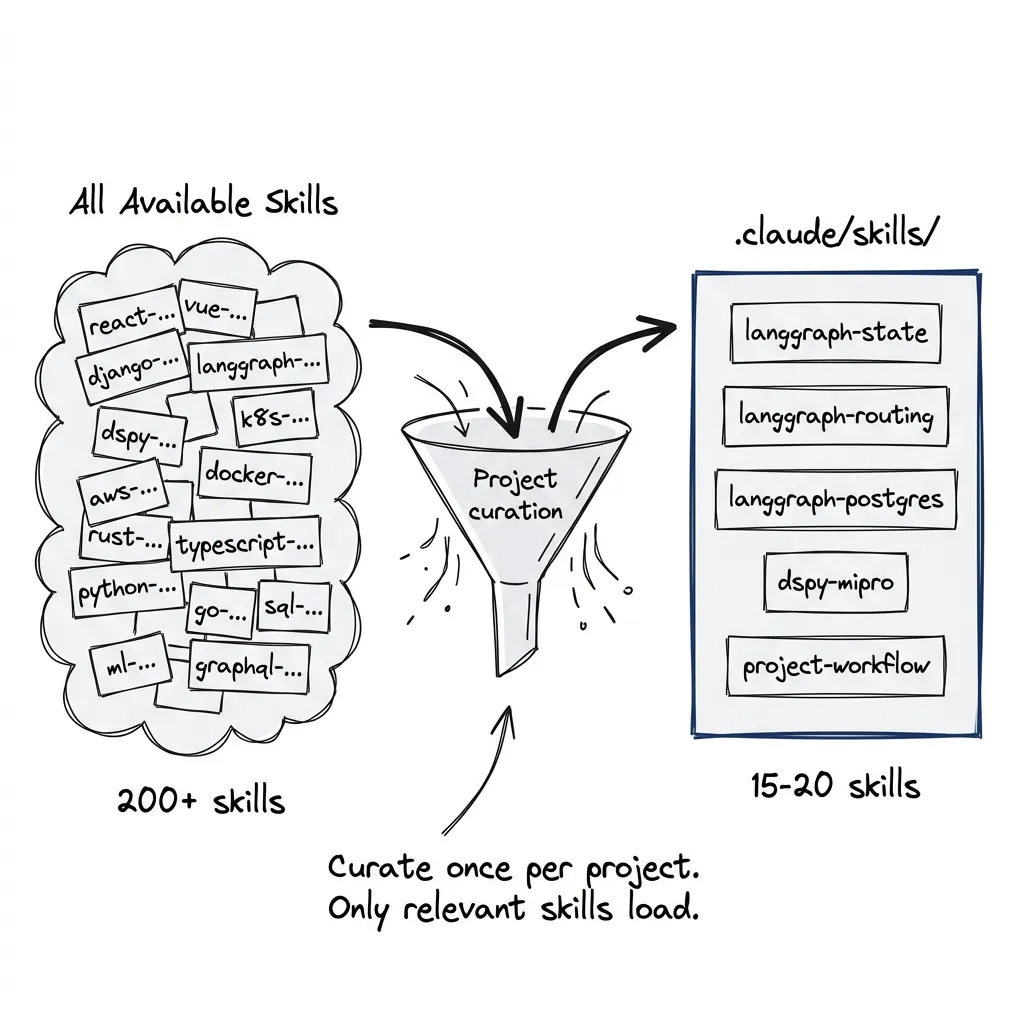
My approach: compile a project-specific pack.
I should mention how I tested this. I was building a sales agent for my company and wanted to use my LangGraph plugin. But instead of jumping straight into that project, I built something simpler first. A recursive image generation tool with feedback loops. Much smaller scope. The idea was to sharpen the patterns on a contained problem before creating a mess in the actual project.
Good decision. The simpler project surfaced a lot of shortcomings in my skill organization. Fixed those. Then applied the lessons to the sales agent.
The point: a project pack contains only the skills relevant to that project’s stack. Building a LangGraph app with DSPy optimization and Postgres persistence? Your pack:
- LangGraph core skills (state, routing, streaming)
- LangGraph persistence skills (Postgres checkpoint)
- DSPy optimization skills (MIPROv2, evaluation)
- Your project-specific workflows
Maybe 15-20 skills. Not 200.
The pack lives in .claude/skills/. Claude auto-discovers skills there. Nothing else loads. You curate what’s present, copy only what the project needs, and delete the rest.
You’ve reduced the search space from “every skill that exists” to “skills this project actually uses.” Vector collapse much less likely with 20 disjoint skills instead of 200 overlapping ones.
The Router Myth
Automatic routing is unreliable.
Semantic similarity between descriptions doesn’t predict which skill should handle a request. Descriptions are short. Embeddings noisy. Edge cases everywhere.
Most people learn this the hard way. My systems don’t rely on automatic routing. Explicit invocation instead.
Workflows call skills by name:
## Implementation Workflow
1. Check requirements → if unclear, invoke /brainstorming
2. Plan implementation → design in beads task
3. Execute → invoke /subagent-driven-development for complex tasks
4. Validate → invoke /qc-validator before closing
5. Complete → invoke /session-completion for git pushThe workflow knows which skill at each step. No guessing. No semantic matching. Direct invocation.
Skill names become command vocabulary. /test-driven-development means something specific. /beads:workflow means something specific.
Automatic discovery isn’t useless. For simple cases, fine. Complex work? Explicit control. Build that into workflows.
Quality Gates for Skills
Skills need quality discipline like code.
Building a plugin with many skills, you need checks:
Schema validation. Every skill has required fields: name, description, version. Description must include trigger phrases. Missing fields, build failure.
Uniqueness check. No two skills with same intent. Run similarity detection across descriptions. Two skills above 80% semantic similarity? Flag for review. (I’m not certain 80% is the right threshold… might be 70%. Still experimenting.)
Collision detection. Check trigger phrases across skills. “State management” in two different skills’ triggers? Collision. Fix it.
Contradiction detection. Skills shouldn’t give conflicting advice. Skill A says “always use TypedDict,” skill B says “prefer dataclasses”? That’s a contradiction. Hard to detect automatically, easy to spot in review.
Staleness check. Skills reference specific APIs. APIs change. Examples break silently.
I don’t automate staleness checks in CI. Built meta-skills instead: skill-qa-audit and skill-perfection. When I suspect drift or want to verify quality, invoke them on demand. They run examples, check for outdated patterns, surface problems.
First four checks can be scripted. Staleness requires judgment. A meta-skill handles judgment better than a bash script.
Cross-Referencing Without Duplication
Skills need to reference each other without copying content.
Copying state management explanation into every skill that touches state? Wrong approach.
Reference the authoritative skill instead:
## State Requirements
Before proceeding, ensure your state schema is properly defined.
See: langgraph-dev-state-management for state design patterns.
This skill assumes you have:
- A Pydantic model for state
- Proper Annotated fields for aggregation
- No dict serialization (use models directly)Skill states what it assumes, points to where that’s documented, doesn’t repeat.
This helps Claude understand how skills work together. “See: langgraph-dev-multi-agent-supervisor for coordination patterns” teaches the relationship between skills. Builds a mental model of the plugin as coherent system, not isolated files.
Each skill authoritative for one thing. Others reference that authority.
Plugin Structure
My LangGraph plugin:
langgraph-dev/
├── langgraph-dev-state-management/
│ ├── SKILL.md # Main content
│ ├── references/ # Deep-dive docs
│ └── examples/ # Runnable code
├── langgraph-dev-conditional-routing/
│ └── SKILL.md
├── langgraph-dev-tool-calling/
│ └── SKILL.md
└── ... (21 skills total)Each skill has:
- Main SKILL.md with the protocol
- Optional references/ for advanced content
- Optional examples/ for runnable code
Claude auto-discovers when the directory is present. No config file.
21 skills, zero overlap, clear namespacing, explicit cross-references.
When Architecture Fails
Even good architecture breaks down.
Skill sprawl. Keep adding skills for edge cases. “Just one more.” Soon you have 100. Fix: merge related skills, use parametric patterns instead of separate skills per variant.
Boundary creep. Skills gradually expand to cover adjacent concerns. State management starts explaining routing. Routing starts explaining tools. Fix: audit regularly. Skill grows beyond declared scope? Split or prune.
Stale references. Skills reference other skills that got renamed or removed. Fix: automated link checking.
Version drift. Skills assume library version X. Project upgraded to Y. Skills give wrong advice. Fix: version-specific skill sets, or continuous QA against current versions.
Documentation masquerading as skills. Skills that restate official docs. Claude can look that up. Tokens without value. Fix: before adding, ask if Claude would reach this conclusion with a web search. If yes… don’t add it.
The architecture isn’t glamorous. Namespacing isn’t exciting. But this is what separates systems that work at scale from ones that collapse under their own weight.
Part 4: the actual step-by-step process for engineering a skill, including the meta-skills I built for QA and refinement.