I usually run Claude Code on Opus. Earlier today Opus started throwing 500 errors, so I switched to Sonnet to keep working. While I waited for Opus to come back — I had a session queued that needed extended thinking — I figured it was a good time to finally set up the OpenTelemetry pipeline I’d been putting off. I wanted to see where my tokens were going and figure out why I kept hitting the 5-hour cap. Also wanted to understand where the agent goes off the rails so I could write better skills and harness.
If Opus hadn’t gone down, I probably wouldn’t have looked.
The first thing my dashboard showed me: about 95% of my API requests were going to Haiku.
Quick context for anyone not tracking Anthropic’s model lineup: Haiku is the smallest model they ship. Fewest parameters, highest speed, lowest cost — roughly 20x cheaper than Opus per token. It’s built for fast, simple tasks: returning search results, classifying text, quick lookups. Not the model you’d pick for reasoning about code architecture.
I had model: sonnet set in both my global and project settings.json. Every project. No exceptions. And almost every request was Haiku.
Beat One: Panic
What the fuck.
Here’s what the telemetry showed after 24 hours of work across five projects:
- Input Tokens: 2.55 million
- Output Tokens: 2.38 million
- Cache Read Tokens: 451 million
- Estimated Cost: $354
- API Calls: 7,222
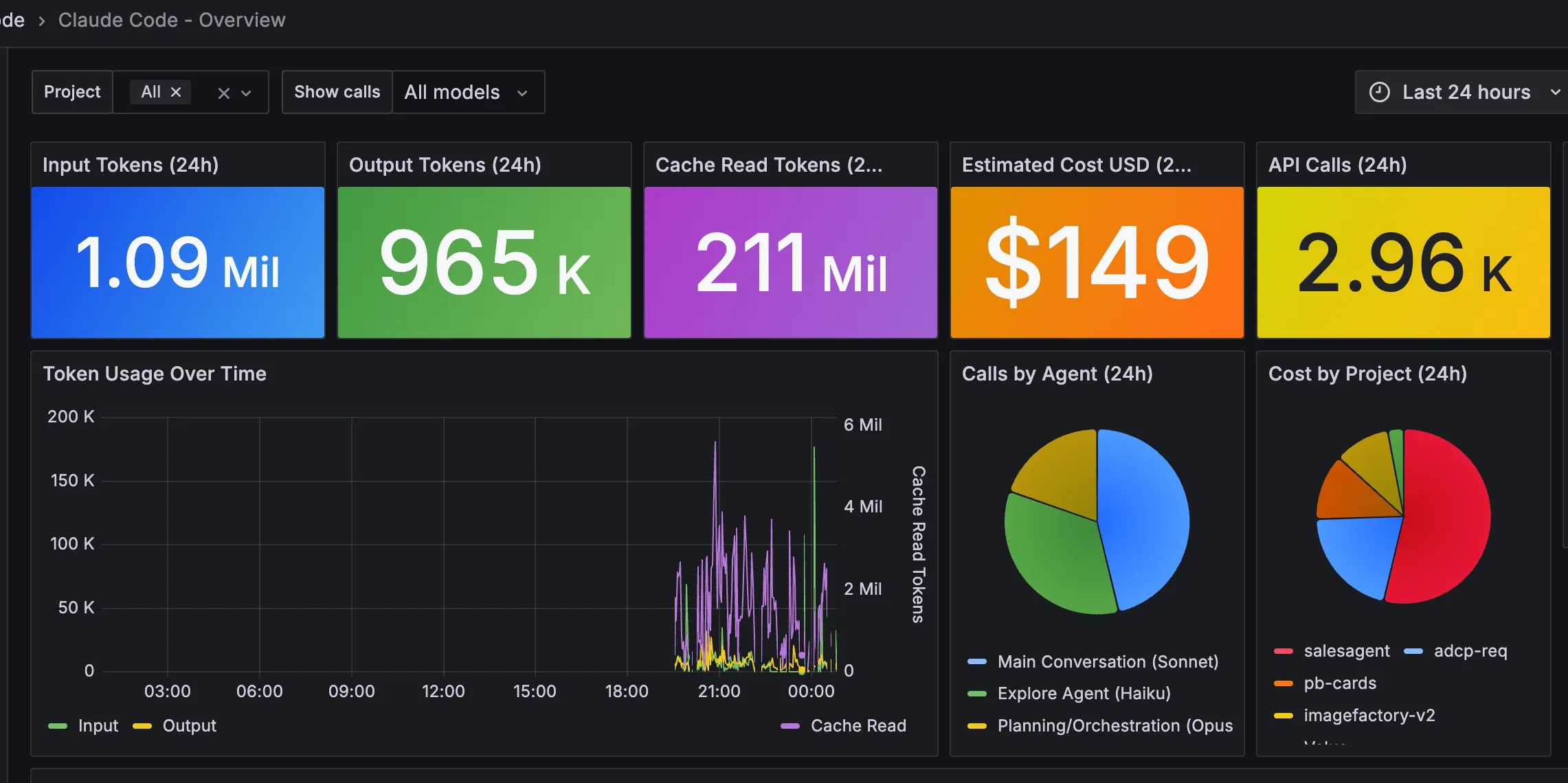
The pie chart labeled “Calls by Agent” had a fat wedge that wasn’t Sonnet. By request count, Haiku dominated everything:
salesagent: Haiku 1,727 Opus 1,657 Sonnet 1,377 (36% Haiku)
pb-cards: Haiku 473 Opus 677 (41% Haiku)
adcp-req: Haiku 197 Opus 302 Sonnet 109 (32% Haiku)
imagefactory-v2: Haiku 112 Opus 25 Sonnet 149 (39% Haiku)In one project, Haiku made more calls than either of the models I chose.
What Happens When You Prompt Claude Code
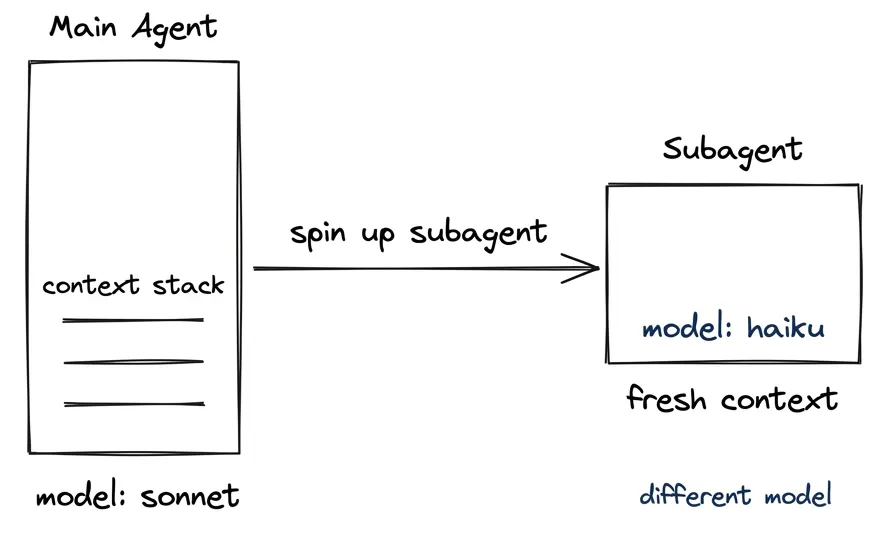
If you haven’t dug into how this works under the hood: when you ask Claude Code to do something — refactor a function, add a feature, fix a bug — it doesn’t just start writing code. First it needs to understand your codebase. It spins up separate sub-processes called subagents, each with its own fresh context window, to do the research: searching for relevant files, reading existing code, figuring out how things connect. Each subagent’s context gets fed to a model. (I wrote about why subagents matter for research and context preservation — the short version is that exploration pollutes your main context, and subagents keep it clean by returning only the conclusions.)
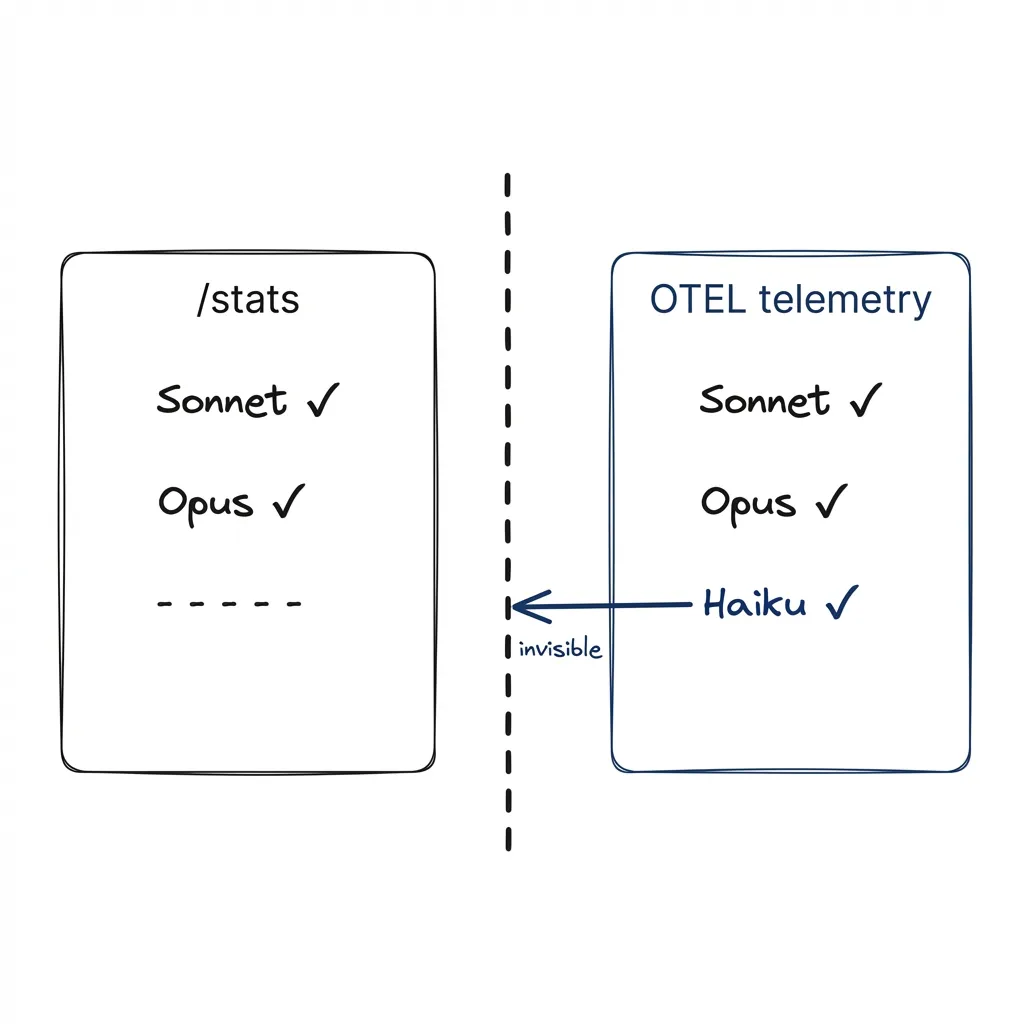
When you set model: sonnet or model: opus, you’d expect that research to run on your chosen model. The research is the hard part — knowing which code to write matters more than writing it. But Claude Code routes that exploration to a different model entirely, without telling you. It doesn’t show up in the UI. It doesn’t count in /stats. The only way to see it is external telemetry.
Beat Two: The Reasonable Explanation
I dug into the logs and found a pattern. Every few seconds during active work, a call would fire with a signature I couldn’t explain:
- Input tokens: somewhere between 300 and 2,000
- Cache reads: zero
- Output tokens: 32
Always 32. Not 31, not 35. Exactly 32 output tokens, every single time. No conversation history, no cache, just a fresh stateless call and a tiny response.
That’s the Explore agent. It’s a built-in subagent hardcoded to Haiku in Claude Code’s cli.js:
LL={ agentType:"Explore", model:"haiku", ... } // line 315538It handles file discovery, code search, codebase exploration. Each call is stateless, fast, disposable. The 32-token output is just a file path or a search result.
Honestly, fair enough. No conversation history, no reasoning needed. Why burn Sonnet tokens on returning a file path? I’d make the same call.
Beat Three: Not All of Them Are Simple
Then I got curious. How do you actually distinguish a simple task from a hard one beforehand? If the logic is “this call will cost more tokens, so route it to Haiku” — that’s a cost decision, not a complexity decision. And the token signatures should tell the story. If Haiku is only doing simple file lookups, every call should look the same: low input tokens, zero cache, exactly 32 tokens out. So I filtered for Haiku calls that didn’t match that fingerprint.
36% of them.
36% of the Haiku subagent calls had token signatures that looked nothing like a file lookup. Input tokens in the 1,000 to 40,000 range. Output tokens well above 32. These weren’t stateless path resolutions. These were calls with input volumes you’d expect from Sonnet or Opus work — architectural analysis, cross-file reasoning, research tasks — running on Haiku.
Worse: 331 of those complex calls had cache reads averaging 79,000 tokens. These aren’t even stateless. They’re reading your accumulated conversation context — the same token signature you see in Sonnet and Opus main conversation calls — on the cheapest model in the lineup.
That’s the number in the title. Not “Haiku handles your file listings.” Haiku handles a real chunk of your exploration work, sometimes with your full session history loaded. The kind of thinking you assumed your chosen model was doing.
The Full Agent Map
Multiple developers verified the hardcoding by inspecting the source. One contributor (GitHub #16594) mapped every built-in agent:
| Agent | Model | Notes |
|---|---|---|
| Explore | Haiku (hardcoded) | File discovery, codebase search |
| Claude Code Guide | Haiku (hardcoded) | Answers “how do I use CC?” questions |
| statusline-setup | Sonnet | Only runs on /statusline |
| Plan | Inherits | Uses whatever you set |
| general-purpose | Inherits | Uses whatever you set |
Setting ANTHROPIC_SMALL_FAST_MODEL in your config doesn’t override the Explore agent. The hardcoding is deliberate.
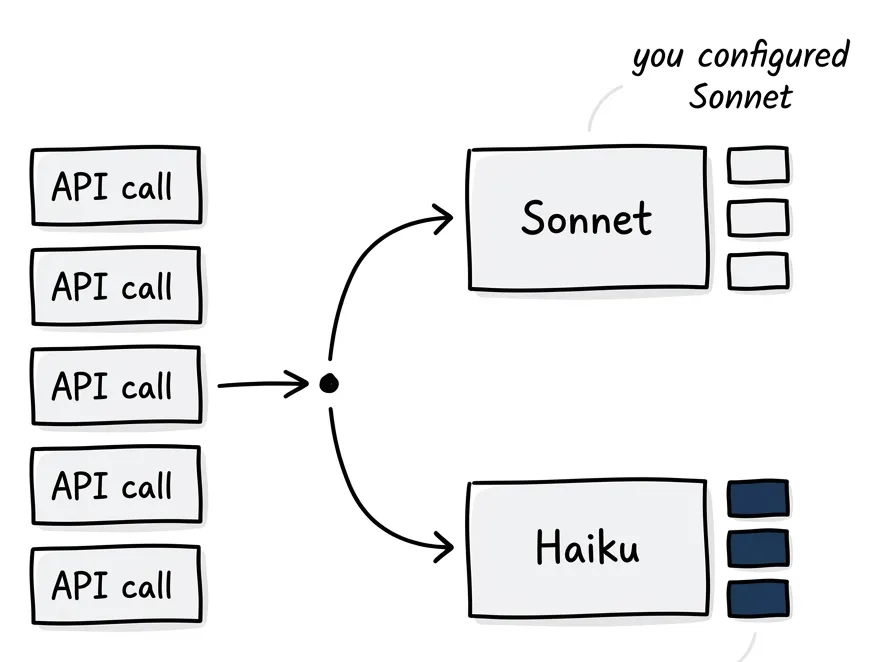
You can tell the agents apart by their token signatures alone:
| Agent | input_tokens | cache_read | output_tokens |
|---|---|---|---|
| Explore (Haiku) | 300 — 2,000 | 0 | 32 (always) |
| Main conv (Sonnet) | 1 | 50K — 140K | 100 — 5,000 |
| Orchestration (Opus) | 1 | 50K — 60K | 70 — 500 |
Sonnet and Opus show input_tokens = 1 because only new content counts — everything else comes from cache. Explore has zero cache because it’s stateless. Fresh lookup, 32 tokens back, done.
The Cache Illusion
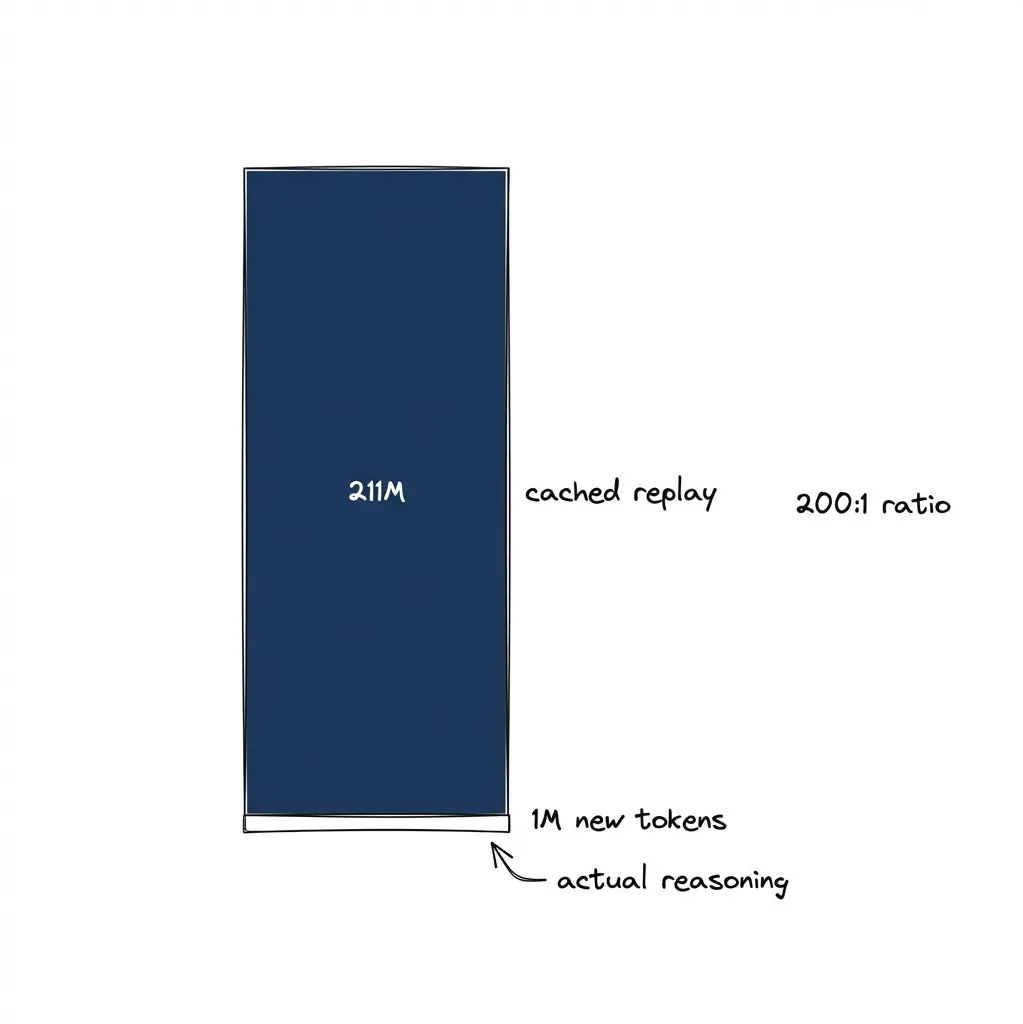
Those 451 million cache read tokens look impressive until you understand what they are.
2.55 million input tokens sounds like a lot of thinking. It’s not. Most of the “thinking” is replayed history. On every API call, Claude Code sends the entire conversation to the API. Anthropic caches the attention tensors for the stable prefix, so on subsequent calls they skip the transformer computation for cached tokens and charge about 10x less than the full input rate.
I traced a single session turn by turn:
seq | cache_read | cache_create | delta
127 | 104,660 | 646 |
129 | 105,306 | 2,895 | 104,660 + 646 = 105,306 ✓
133 | 108,201 | 140 | 105,306 + 2,895 = 108,201 ✓
137 | 108,341 | 1,063 | 108,201 + 140 = 108,341 ✓Each turn’s cache_create becomes the next turn’s cache_read delta. The entire accumulated context is re-read from cache every single call. A 94-call session with an average context of 107K tokens = 10 million cache reads from a session that produced 143K new input tokens and 100K output tokens.
That session ran on Sonnet. Cost: $9.28. Without caching, at full Sonnet input rates ($3/MTok), the same session would have cost ~$30. I normally run Opus ($5/MTok input, $25/MTok output), which would make those numbers even larger.
The numbers everyone fixates on — the ones that make you feel like you’re getting serious compute — are mostly cheap replays. The actual new reasoning per turn is a rounding error against the cache. Those 451 million cache reads in my dashboard? About $135 at Sonnet’s cached rate of $0.30/MTok. The 2.55 million actual input tokens? About $8. Anthropic isn’t doing over a thousand dollars worth of fresh computation. They’re doing maybe $150 worth and the caching architecture handles the rest.
And here’s the kicker: Haiku handled 36.5% of all API calls but accounted for just $8 of the $354 total cost — 2.3%. A Haiku call costs about $0.003 on average. An Opus call costs $0.077. The cost optimization is real. The transparency about it still isn’t.
For API users, this is efficient and transparent. You see the per-token pricing, you understand what you’re paying for. For Max subscribers paying a flat rate, this is the gap between what the product feels like and what it costs to serve. Great marketing, too — those token counters climbing into the millions feel like you’re getting massive value. The raw numbers are real. The compute behind them isn’t what you’d think.
The Tool That Can’t See Itself
This is the part that stung.
Claude Code has a /stats command. Type it, get your session stats: token usage, cost, call counts per model. Except it doesn’t count subagent models. At all.
GitHub #17692: a user created a subagent explicitly set to Haiku. The subagent ran. /stats showed zero Haiku invocations. Screenshots included. Bug is confirmed, still open, currently tagged for auto-close due to inactivity.
The built-in stats don’t show what the tool is actually doing. I only found out because I happened to have an OTEL pipeline running for a different reason.
| What exists | Visible to users? |
|---|---|
| Docs page listing Haiku for Explore | Buried in sub-agents reference |
| Stated cost-saving motivation | Same buried page |
| Opt-out mechanism | Same buried page |
| Marketing page disclosure | Does not exist |
| Terms of Service model guarantee | Does not exist |
/stats showing Haiku calls | Broken (#17692) |
| Status line model indicator | Shows agent name, not model |
The documentation does mention it. On the sub-agents page, under the benefits of subagents:
“Control costs by routing tasks to faster, cheaper models like Haiku”
That sentence names the motivation. For API users, this saves their money. For Pro/Max subscribers paying a flat rate, it saves Anthropic’s.
The Consumer Terms say nothing about model selection:
“We may modify, suspend, or discontinue the Services.”
“We do not guarantee that any particular piece of content, feature, or other service will always be available.”
No promise about which model you get. No requirement to disclose substitutions.
”I Might as Well Be Using Haiku”
Since late 2025, developers have been complaining that Claude is “getting dumber.” Reddit threads about the model ignoring plans, fabricating changes, producing worse code than before. A Hacker News discussion hit 760 points with 355 comments. People blamed server load, context rot, time-of-day degradation.
Nobody connected it to the Explore agent running on Haiku.
Anthropic responded. They acknowledged bugs in Sonnet 4 and Haiku 3.5. Their statement: “We never intentionally degrade model quality.” The bugs were “unrelated.” No mention of the two-model architecture. No mention that a real portion of work users attribute to Sonnet is actually running on Haiku.
One HN commenter wrote: “In these moments I might as well be using Haiku.”
He meant it as a hypothetical.
Meanwhile on Threads, Boris Cherny, Head of Claude Code, posted advice to use Haiku for execution while Sonnet handles planning. He was promoting the mixed-model pattern as a productivity feature. What he wasn’t saying: you’re already in it by default.
The GitHub issues tell the rest. #16594 (hardcoded model names) is still open. The auto-close bot tried to kill it; four people downvoted the bot. #25546 (per-agent model config) was closed as a duplicate. #17692 (/stats bug) is open but flagged for auto-close from inactivity.
Why This Stings
I’ve spent months optimizing how my agent explores codebases. Better prompts, structured documentation, deterministic task management — all of it trying to reduce the time and tokens it takes to understand a problem before solving it. Exploration is where the real value is. Knowing which code to write matters more than writing it.
Now I find out the thing doing all that exploration was running, in at least 36% of cases, on the smallest model in the lineup.
What I Want to See
The architecture decision is defensible. Fast, stateless lookups don’t need Opus. I’d do the same thing.
The opacity is the problem.
Fix /stats so it counts all model invocations, including subagents. #17692 has been open since January. Upvote it before it auto-closes.
Show the model in the status line. When Explore runs, show “Explore (Haiku)” not just “Explore.” Let me see what’s happening.
Add a settings option for subagent model overrides — something like CLAUDE_CODE_EXPLORE_MODEL=sonnet. Don’t make me replace the entire agent definition to change one parameter.
And disclose it on the marketing page. If 36% of subagent calls use a different model, that’s a material fact about the product.
The Fix
You have two options.
Option 1: Disable Explore entirely
{ "permissions": { "deny": ["Task(Explore)"] } }Add this to .claude/settings.json. All exploration runs on your main model. You lose the context-separation benefit — sub-agent results will pollute your main conversation — but every call uses the model you selected.
Option 2: Override the Explore agent
Create ~/.claude/agents/Explore.md:
---
model: sonnet
---
Your system prompt for exploration here.This replaces the built-in Explore with your own version running on Sonnet. The trade-off, as one developer put it in #25546: you’re “losing the carefully crafted prompts from Anthropic.” But you gain the model you’re paying for.
This is what I’m running now. It’s early. Even subjectively, exploration results feel more thorough. Hard to A/B test a coding agent. The token signatures confirm Haiku calls are reduced, but I still see some Haiku in my telemetry even after the override. Not fully sure this catches every code path.
How to Check Your Own Setup
Set up OTEL telemetry. Claude Code has built-in support — you just need a collector endpoint. Pipe to Loki, query with LogQL, visualize in Grafana. Once you see the data, you’ll form your own opinion about whether the current routing makes sense for your workflow.
I’ll keep using Claude Code. Still the best coding agent I’ve worked with. But when I set model: sonnet, I’d like that to mean something.
As per the disclosure on this blog, this article was co-created with Claude. I hope it was Opus.